Creating a New Env
This tutorial explains how to create, register, and use a new EvoGym environment. Completed code can be found here.
Page Outline
- Introduction
- Designing the Environment
- File Structure
- Writing the Environment Class
- Registering the Environment
- Visualization Script
Introduction
Let’s get started! We’re going to be making an environment for the “walking” task, similar to Walker-v0. This tutorial assumes that you have followed setup instructions for both EvoGym and the Evolution Gym Design Tool.
Designing the Environment
We can specify the voxel structure of our new environment with the Evolution Gym Design Tool. The Design Tool enables us to design environments visually, instead of specifying all objects in code.
Since we’re designing a “walking” task, our environment needs two objects: a robot and a ground. In the Design Tool, we’ll just create the ground object – we will add the robot object in code because we want it to be highly customizable.
Launch the Design Tool from its repo’s main folder:
python src/main.py
Follow the steps to create your “walking” environment:
- In the right panel, update the
Grid Sizeto(width = 30, height = 1) - In the right panel, switch the
Edit ModetoVoxel Modeand selectFixed Voxelfrom the dropdownVoxel Selector - In the left panel, fill in all the grid cells with fixed voxels by clicking on them and dragging your cursor. This object will be the ground
- Change the
Edit ModetoSelect Modeand select the ground object. Name itgroundin the panel on the right - In the right panel, name the environment
simple_walker_env.jsonand hit save
The result should look something like this:
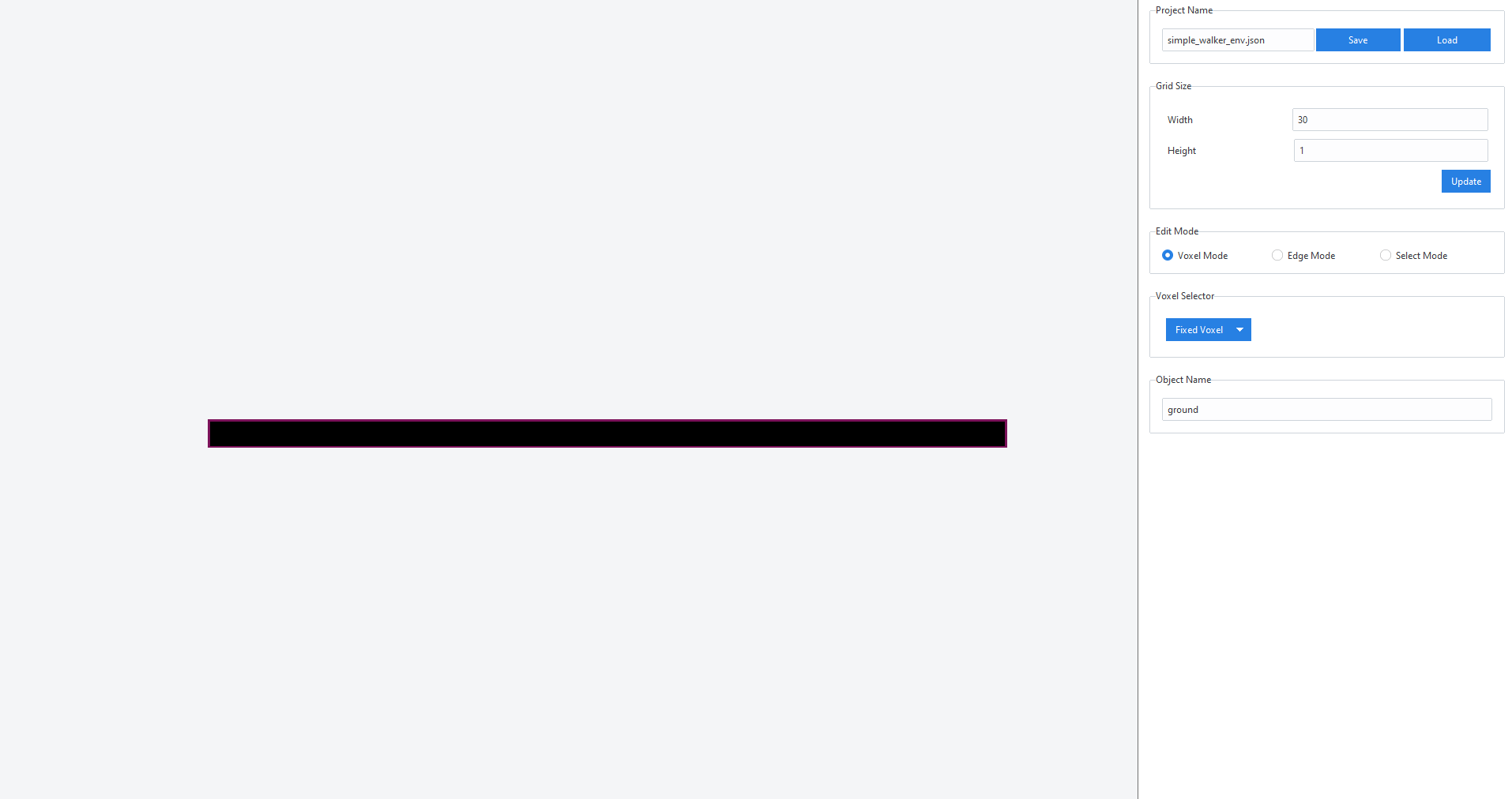
File Structure
The file simple_walker_env.json should be saved in the exported folder in the Design Tool repo. Create the following file structure in the directory of your choice:
tutorials
├── envs
│ ├── __init__.py
│ └── simple_env.py
├── world_data
│ └── simple_walker_env.json
└── visualize_simple_env.py
In simple_env.py we will write the code for our environment and specify the observation, reward, and action space. In __init__.py we will register the environment. Finally, we will see our environment in action in visualize_simple_env.py.
Writing the Environment Class
The majority of the work in creating a new environment comes in writing the environment class which we will do in simple_env.py. Careful consideration should go into designing your environment’s observation and reward as these can significantly impact the performance of co-design or control optimization algorithms you intend to run. The structure of our environment class will be as follows:
from gym import spaces
from evogym import EvoWorld
from evogym.envs import EvoGymBase
import numpy as np
import os
class SimpleWalkerEnvClass(EvoGymBase):
def __init__(self, body, connections=None):
...
def step(self, action):
...
return obs, reward, done, {}
def reset(self):
...
return obs
Note that our environment class, SimpleWalkerEnvClass, inherits from EvoGymBase, the superclass of all EvoGym environments.
Init
In the init method, the body and connections of the robot we would like to simulate are passed in. We initialize an EvoWorld object with data from world_data/simple_walker_env.json, and also add our robot to position (1, 1) of the EvoWorld. We pass the completed EvoWorld object to initialize the superclass EvoGymBase.
self.world = EvoWorld.from_json(os.path.join('world_data', 'simple_walker_env.json'))
self.world.add_from_array('robot', body, 1, 1, connections=connections)
EvoGymBase.__init__(self, self.world)
Next, we need to set the observation and action space for our environment. By bounding the action space to [0.6, 1.6], we limit the compression and expansion of each of the robot’s actuators to 60% and 160% of their original size, respectively.
num_actuators = self.get_actuator_indices('robot').size
obs_size = self.reset().size
self.action_space = spaces.Box(low= 0.6, high=1.6, shape=(num_actuators,), dtype=np.float)
self.observation_space = spaces.Box(low=-100.0, high=100.0, shape=(obs_size,), dtype=np.float)
Finally, each EvoGym environment comes with a built-in viewer. We set it to track the robot object to make the visualization look pretty :D
self.default_viewer.track_objects('robot')
Step
In the step method, we need to step the simulation and compute actions and rewards. We start by stepping the simulation with the robot’s action. Notice that we collect information about the position of our robot before and after the step.
pos_1 = self.object_pos_at_time(self.get_time(), "robot")
done = super().step({'robot': action})
pos_2 = self.object_pos_at_time(self.get_time(), "robot")
Also notice that super().step() returns a done flag. When this is True, the simulation has reached an unstable state from which it cannot recover. We will handle this in the reward computation.
To compute the robot’s reward, we subtract the x-position of the robot’s center of mass before and after stepping the simulation. This way, the robot is rewarded for moving in the positive x direction. Note that pos_1 and pos_2 contain position information about each point in the robot object, so we take an average to get the position of the robot’s center of mass.
com_1 = np.mean(pos_1, 1)
com_2 = np.mean(pos_2, 1)
reward = (com_2[0] - com_1[0])
Next, we handle special cases in the reward computation. A large negative reward is returned whenever the simulation enters a terminal state, and a large positive reward is returned if the robot achieves the goal. In this case, the goal is for the robot reach the end of the ground object, which is 30 voxels long.
if done:
print("SIMULATION UNSTABLE... TERMINATING")
reward -= 3.0
if com_2[0] > 28:
done = True
reward += 1.0
Finally, we compute the observation and return all relevant data. In this example, the returned observation consists of two parts. get_vel_com_obs returns the velocity of the robot’s center of mass. get_relative_pos_obs returns the positions of the robots’s point masses relative to the robot’s center of mass. You can read more about built-in observation helper functions here.
obs = np.concatenate((
self.get_vel_com_obs("robot"),
self.get_relative_pos_obs("robot"),
))
return obs, reward, done, {}
The last return value is for debugging information.
Reset
In the reset method, we first reset the simulation. Then we return the same observation as done in step.
super().reset()
obs = np.concatenate((
self.get_vel_com_obs("robot"),
self.get_relative_pos_obs("robot"),
))
return obs
Registering the Environment
We register the environment in __init__.py using functionality provided by OpenAI Gym. In this file, we can register many environments by calling register for each environment as desired, but in this example we just register one.
from envs.simple_env import SimpleWalkerEnvClass
from gym.envs.registration import register
register(
id = 'SimpleWalkingEnv-v0',
entry_point = 'envs.simple_env:SimpleWalkerEnvClass',
max_episode_steps = 500
)
In the registration, SimpleWalkingEnv-v0 is our environment’s name and we’ve set it to run for 500 steps before resetting. entry_point tells gym where to find the class specification of our environment.
Visualization Script
We’re almost there! We will write the visualization script in visualize_simple_env.py. We use evogym.sample_robot to sample a random 5x5 robot and gym.make to create an instance of SimpleWalkingEnv-v0 with our sampled robot. We step the environment 500 times. In each iteration, we sample a random action vector for our robot, step the environment, and render it.
import gym
from evogym import sample_robot
# // import envs from the envs folder and register them
import envs
if __name__ == '__main__':
# // create a random robot
body, connections = sample_robot((5,5))
# // make the SimpleWalkingEnv using gym.make and with the robot information
env = gym.make('SimpleWalkingEnv-v0', body=body)
env.reset()
# // step the environment for 500 iterations
for i in range(500):
action = env.action_space.sample()
ob, reward, done, info = env.step(action)
env.render(verbose=True)
if done:
env.reset()
env.close()
From within the directory containing visualize_simple_env.py run
python visualize_simple_env.py
and enjoy!